This post was written as part of a partnership between Global Voices and Monument Lab. Global Voices is an international and multilingual community of writers, translators, academics, and human rights activists.

“Damascus-Old City - Umayyad Mosque- دمشق- المدينة القديمة - الجامع الأموي,” Damascus before the war. (Hani Zaitoun (CC BY-SA 3.0))
One of the most haunting images of war in the modern era shows five young children running barefoot from a cloud of smoke, northwest of Saigon. At the center is a girl who is completely naked, screaming in pain from a napalm bomb that South Vietnamese troops, propped up by the US military, had mistakenly dropped on her village.
“The Terror of War” also known as “Napalm girl” was captured by Associated Press photographer Nick Ut in 1972 and appeared in major newspapers across the world, including the New York Times.
Although it went against the Times’ and other newspapers’ policies to show a photograph of a naked child, editors made an exception because of the illustrative nature of the image. The photo later won a Pulitzer prize and left an enduring mark on public understanding of the Vietnam War and its consequences for civilians.
In 2016, this very same photo was censored on Facebook. The image was uploaded by Aftenposten, Norway’s largest newspaper, as part of a historical review of the war. It was censored by Facebook almost immediately afterwards, because it depicted a naked child.
In response, Aftenposten editor-in-chief Espen Egil Hansen wrote an open letter to Facebook CEO Mark Zuckerberg imploring him to “envision a new war where children will be the victims of barrel bombs or nerve gas. Would you once again intercept the documentation of cruelties?”
Facebook soon thereafter reinstated the image. In an interview with The Guardian, a PR spokesperson explained that Facebook had changed its decision because the image of the girl, Kim Phuc, was “an iconic image of historical importance.”

Smoke rises from a building in the Damascus suburb of Jobar after being hit by a hit by a bomb during the Qaboun offensive (February–March 2017). (Qasioun News Agency (CC BY 3.0))
‘Envision a new war’
There is no need to envision or imagine this “new war” that Hansen described in his plea to Zuckerberg. It is already happening, in Syria.
I recently watched a series of videos showing the aftermath of a sarin gas bombing in Idlib province, in 2017. Several of them show chaotic scenes at a medical center. In one, a teenage boy lies on the floor, barely conscious, with foam oozing from his mouth, a telltale sign of sarin gas exposure. Another shows a little child of maybe three or four years who is lying on a table in a medical center. A man stands over him and explains in Arabic how the child succumbed to the deadly gas. The man keeps his face out of the frame.
These are a just few of thousands, perhaps millions of videos of this kind. Syria’s may be one of the most documented wars in human history. How will this overabundance of videos and pictures affect how the war is understood in the future? And what consequences will they bring for the war’s perpetrators?
While it has become increasingly difficult and dangerous for professional media outlets like AP or the New York Times to cover Syria’s civil war, it is being thoroughly documented all the same. With mobile phones in hand, Syrians have been recording and photographing bombings, shellings, nerve gas and chemical weapon attacks and uploading these images to the internet. The video I mentioned above was taken by SMART News Agency, a group known for documenting the work of the White Helmets in Aleppo.

A collage of images of chemical weapon attacks and victims. (Adam Harvey, Syrian Archive (CC BY-SA 4.0))
Millions of media files are moving around online, and constantly shifting public understanding of the war and its effects on people’s lives. This abundance of documentation has the potential to serve as testimony for the public record and even evidence of war crimes, if regime leaders are one day brought before the International Criminal Court. It has the power to provide the public with a collage of information and memory of the war, the people whose lives it changed and took away, and the place where all this happened.
But the sheer abundance of material at hand — tens of millions of files and counting — is almost impossible to parse or search without guidance.
A group of technologists in Berlin is trying to change this, one media file at a time.
Building the Syrian Archive
Syrian technologist Hadi Al-Khatib left his country for Berlin, Germany in 2011. Later that year, he began helping a group of Syrian lawyers who were trying to gather evidence of human rights violations at the start of the war. The group was overwhelmed with data from digital media files and had no strategy for verifying or classifying the abundance of digital media that was already pouring out of the country.
This was in 2011, at the peak of the social uprisings that spread across the Arab region, changing the course of history in Egypt, Tunisia, Syria and beyond. Al-Khatib had seen firsthand how digital documentation of human rights violations could spark protest and shift public understanding of major events in a country’s history.
But he also knew how complicated this kind of documentation could become. The world’s most accessible social media platforms were optimized for clicks and advertisements, but not for verification, categorization or contextual understanding.
When he returned to Berlin, Al-Khatib recruited a few colleagues to figure out how they could help. The trio spent the next three years collecting, verifying and categorizing digital media files from the war.
In 2014, they launched the Syrian Archive, a public database that today contains more than five million images and video files from the war.
The Syrian Archive is not your average online library. The homepage features investigations of airstrikes by Russian planes, chemical attacks, and shellings that have destroyed hospitals, bakeries and mosques.
The site highlights evidence of chemical weapons attacks, which are forbidden under international humanitarian law.
The keywords and categories one uses to search the archive offer a stark sense of its holdings. One can search videos of attacks by the type of weapon used — barrel bombs, cluster munitions, drones and sarin gas are among just a few of the options in the “weapons used” drop-down menu.
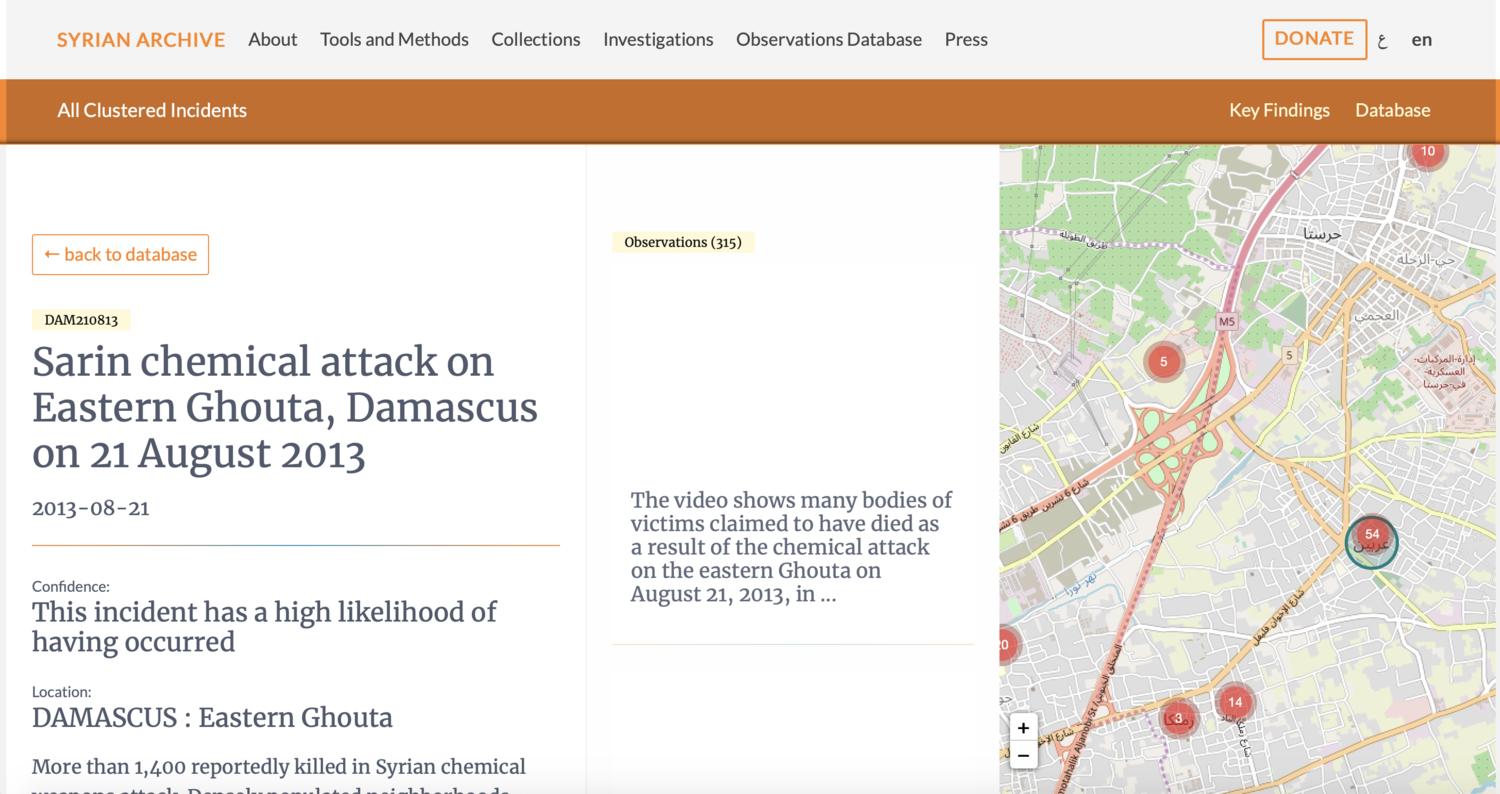
Screenshot of entry “DAM210813, Sarin chemical attack on Eastern Ghouta, Damascus on 21 August 2013,” one of the entries in the Syrian Archive’s collections database. (Syrian Archive)
Browsing the archive, one gets the sense that this kind of work should be in the hands of a UN agency or international humanitarian organization. But as the archive’s materials note, these institutions have not kept up with the pace of this war. The French Foreign Ministry and the UN Commission of Inquiry into Syria have confirmed that 163 chemical weapons attacks have taken place in Syria. The Syrian Archive has documented 212.
If they don’t do this work, Al-Khatib says, the materials — and everything they can tell us about the war — may soon become impossible to check or verify. Some of it may be lost altogether.
“This data is useless if it’s not labeled or searchable,” Al-Khatib told me when we met in Berlin last month. “But if there’s context, there are lots of things we can do.”
The goal of their work, most immediately, is to provide journalists and human rights workers with datasets that are searchable, verified and contextualized by local and subject matter experts. In a not-too-distant future, the group expects these videos and images will serve as evidence in war crimes cases against the parties involved, thanks in part to partnerships with the UN High Commission on Human Rights and the Human Rights Center at UC Berkeley Law School.
Beyond preserving evidence, Al-Khatib also envisions the archive offering future generations rich material for reconstructing, historicizing and memorializing the war, the people whose lives it changed and took away, and Syria as a country.
“For me, what is most important is to make sure this data is going to be available for the next 10, 20 years,” he says. “I imagine this could contribute to a museum, or a digital memory space.”
But right now, the team has little time to make meaning or narratives from these images. They just know that the images need to be preserved.
Images of war are disappearing in Silicon Valley
To gather this data, Al-Khatib and his colleagues work directly with local journalists and humanitarian groups documenting the war. They rely heavily on Facebook and YouTube as the primary platforms where these groups and countless individuals upload their files. They estimate that 90% of the media files in the archive come to them by way of these two behemoth social media services.
He and his colleagues have identified several hundred sources across the social web, mainly Facebook pages and YouTube channels, from which their systems automatically capture images and videos each day. This allows them to classify and archive material in ways that these corporate platforms are not built to accommodate.
But increasingly, they are capturing files not only for the sake of archiving them, but to prevent them from disappearing altogether.

The Syrian Archive team, including Hadi Al Khatib, right. (Syrian Archive (CC BY-SA 4.0))
Faced with rising pressure from governments to rid their networks of violence and hatred, companies like Facebook and Google (parent company of YouTube) are scrambling to censor graphic violence and anything that could be linked to violent extremist groups like ISIS. Thousands of videos and photos from the Syrian war have disappeared along the way.
Videos that could be used as evidence against perpetrators of violence have been deleted upon upload, or censored by the companies shortly after they are published. They are often impossible to replace.
Al-Khatib says they have to do better than this. “The companies have a responsibility to preserve these materials,” he says. “It’s evidence.”
He explains that right now, there are only small, partial solutions to the problem. For example, YouTube allows users to reclaim videos that they’ve uploaded, but which were rejected for violating the company’s rules prohibiting extreme graphic violence.
But, he asks: “What if the source is not alive? What if the source is arrested? What if the source doesn’t have access to email?” These are incredibly common predicaments in Syria.
And there is a great deal of material that never even sees the light of the public internet. We talk about how Google uses machine learning technology to scan videos for terms of service violations, like extreme graphic violence. In some cases, videos are rejected and purged from the site before they even become public.
“We have no idea what doesn’t make it onto the site,” Al-Khatib says. “We don’t know everyone. So if they don’t keep it [on their devices], that’s that.” He seems to care deeply about every video, as if each one is part of the story.
Among the millions of files, there are surely some that could one day become “iconic image[s] of historical importance,” rising to the level of Nick Ut’s photo of the young Kim Phuc running for her life.
But if the person who captures them puts them into the hands of companies like YouTube and Facebook — and then loses her device, or even her life — the image may be lost forever.

“Aleppo City at Night,” Aleppo before the war. (Anas A via Flickr)
How is technology telling our history?
While millions of people have the power to capture these images, a mere handful of privately-owned and operated companies have the power to decide what becomes public and what does not. With minimal regulations or accountability mandates to comply with under US law, and increasing pressure to keep violence off of their networks in Europe, companies are routinely disposing of this material.
Who is actually reviewing these videos and deciding what stays and what goes? Sometimes companies pay people to do this work, but over the past two years, machine learning tools and other types of artificial intelligence have become a favored (and more affordable) solution to this problem. While AI tools are very good at recognizing the content of an image — such as a naked child, in the case of Kim Phuc — they may never have the capacity to judge its context or legal significance.
Unlike Ut’s photograph, carefully considered and contextualized by Ut and his editors at AP, images from the Syrian war increasingly are at the mercy of technical systems — not human ones — that decide which images to allow and which ones to censor.
How should social media companies contend with this abundance of images and video circulating online, some of which may serve as vital evidence of war crimes or human rights violations? And how can people who witness these events document and preserve them in the interest of public knowledge?
The Syrian Archive may be setting the course for developing a new kind of public space online, moving away from the Silicon Valley models that are all built to generate attention for the sake of ad revenue.
What if we had a “social media” space where information was organized based on its context, legal significance and cultural meaning? How might we see the present time, and the past, differently?
The Syrian Archive offers one possible answer to this question. While the future of its subject matter remains painfully uncertain, there is some light in knowing that in the years to come, those who want to tell stories of Syria will have this rich archive of data and stories from which to draw.